
Tutorial : Hadoop -- Main Thread
@neeraj-iAaNcG
•
Oct 14, 2024
Oct 14, 2024
1.2K
Well, I have decided to come over and post stuff that I manage to collect and learn as I go ahead with my Hadoop practice. This thread will be an introduction to what Big Data and Hadoop are and will contain links of other threads that I am going to post so that it leads to easy navigation and a structured learning experience for readers.
INDEX
#-Link-Snipped-#
#-Link-Snipped-#
#-Link-Snipped-#
Introduction to Hadoop and Big Data
Imagine a scenario wherein you have a Gigabyte of data that you want to process and you have a desktop computer with an RDBMS. The desktop computer will have no problem handling this load. Then your firm starts to grow very quickly and the data goes from 1GB to 10GB and then 100GB. This is when you start to reach the limits of your desktop computer.
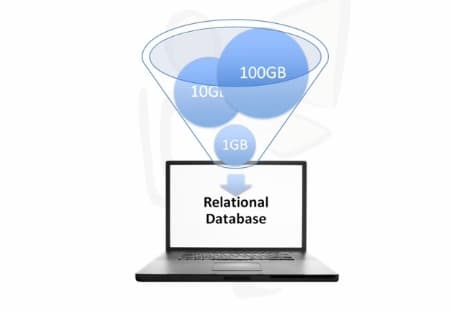
Suppose you invest some money and get in a bigger computer with more processing power then you can process up to 10 TB to 100 TB and then you approach the limits of this computer too. Also, now you are asked to feed your application with unstructured data as well coming from Facebook, Sensors, RFID readers etc.

Now, how can you handle this huge amount of data? Hadoop lets you do so.
Hadoop is an open source project of Apache Software Foundation. Its a framework written in Java developed by Doug Cutting and he named it after his son's toy elephant.
Hadoop uses Google's MapReduce and Google's file system technologies as its foundation.
It is optimized to handle massive amounts of structured and unstructured data with the use of hardware that are relatively inexpensive computers. It is capable of doing massive parallel processing but that being a batch process, the response time is not immediate.

Hadoop replicates its data among different computers so that if one computer goes down, the data can be processed from another computer. This is called Mirroring or RAID 2 architecture.
Hadoop is not suitable for OLTP loads where data is randomly scattered on a structured data platform like RDBMS. Hadoop can also not be used for OLAP loads where data is sequentially accessed on a structured data platform to generate reports that provide business intelligence.
Hadoop is used for Big Data. It compliments OLTP and OLAP. It is in no way a replacement to RDBMS.
So now what is Big Data?
Big Data is a term used to describe large collections of data (also known as datasets) that may be unstructured, and grow so large and quickly that it is difficult to manage with regular database or statistics tools.
Now with all the advantages of Hadoop there are some cons too. As Hadoop processes data randomly, it is not suitable for processing transactions. It doesn't suit low data latency scenarios and is also not good where work cannot be parallelized.
Please post in any doubts or comments that you have and look out for the index section of this post to go to other tutorials
INDEX
#-Link-Snipped-#
#-Link-Snipped-#
#-Link-Snipped-#
Introduction to Hadoop and Big Data
Imagine a scenario wherein you have a Gigabyte of data that you want to process and you have a desktop computer with an RDBMS. The desktop computer will have no problem handling this load. Then your firm starts to grow very quickly and the data goes from 1GB to 10GB and then 100GB. This is when you start to reach the limits of your desktop computer.
Suppose you invest some money and get in a bigger computer with more processing power then you can process up to 10 TB to 100 TB and then you approach the limits of this computer too. Also, now you are asked to feed your application with unstructured data as well coming from Facebook, Sensors, RFID readers etc.
Now, how can you handle this huge amount of data? Hadoop lets you do so.
Hadoop is an open source project of Apache Software Foundation. Its a framework written in Java developed by Doug Cutting and he named it after his son's toy elephant.
Hadoop uses Google's MapReduce and Google's file system technologies as its foundation.
It is optimized to handle massive amounts of structured and unstructured data with the use of hardware that are relatively inexpensive computers. It is capable of doing massive parallel processing but that being a batch process, the response time is not immediate.
Hadoop replicates its data among different computers so that if one computer goes down, the data can be processed from another computer. This is called Mirroring or RAID 2 architecture.
Hadoop is not suitable for OLTP loads where data is randomly scattered on a structured data platform like RDBMS. Hadoop can also not be used for OLAP loads where data is sequentially accessed on a structured data platform to generate reports that provide business intelligence.
Hadoop is used for Big Data. It compliments OLTP and OLAP. It is in no way a replacement to RDBMS.
So now what is Big Data?
Big Data is a term used to describe large collections of data (also known as datasets) that may be unstructured, and grow so large and quickly that it is difficult to manage with regular database or statistics tools.
Now with all the advantages of Hadoop there are some cons too. As Hadoop processes data randomly, it is not suitable for processing transactions. It doesn't suit low data latency scenarios and is also not good where work cannot be parallelized.
Please post in any doubts or comments that you have and look out for the index section of this post to go to other tutorials