Tutorial: Indexes In Oracle
@neeraj-iAaNcG
•
Oct 23, 2024
Oct 23, 2024
1.8K
Let's try to understand what are indexes in oracle or any database. Consider a general scenario that we encounter in our daily life.. Suppose I have a book with me about C programming and Data structures which consists of 700 pages. I want to study about file concepts in C. Now, how can I find where I have the information in the book that I want? I need to go searching page by page and search for the concept that I require right? This consumes a lot of time. To avoid this time wastage, books come with an index that stores the page numbers against the name of each chapter,unti etc. This index helps us in saving hell lot of time because we can directly go to the page that we want.
Same applies in databases too. An index is used to avoid wastage of time that is spent in searching for a particular record in a table.
For example, consider the following table
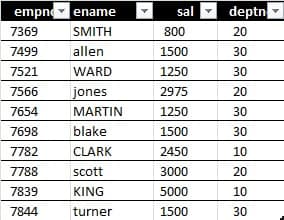
If you run the following query on this table:
select * from emp where empno=7844;
it will go and scan each and every block of data starting from the top row till bottom row and when it finds empno 6844, it gives the result. This is a small table, consider the same operation on a table with 10 million rows, it will definitely consume a lot of time. This can be reduced by using index. An index can be created as follows:
create index ind_1 on emp(empno);
In the above statement, we are telling oracle to create an index named ind_1 on empno filed of table emp.
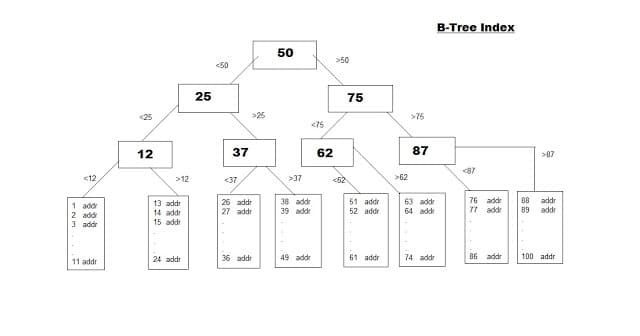
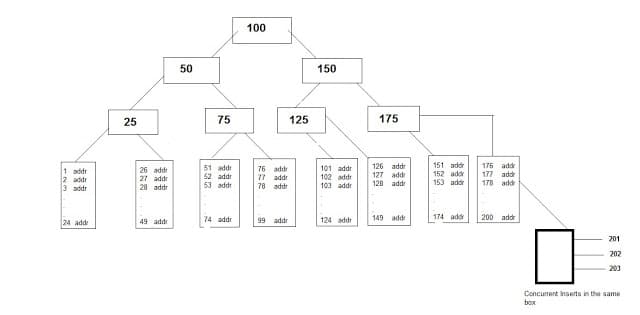
When this index is created, one more table is formed in the back end that stores the address of each and every row. Following diagram will give a clean idea about it:
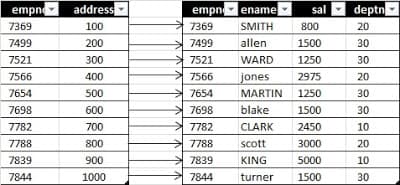
As shown in the diagram, every empno has a corresponding address which holds the address of each row of the emp table. Now whenever we want to extract row corresponding to a particular empno, we get the row very fastly compared to earlier method where we had no index.
This is how indexes are helpful in databases..
There are mainly four type of indexes which I will be discussing further in the comments.
They are:
--> B-Tree Index
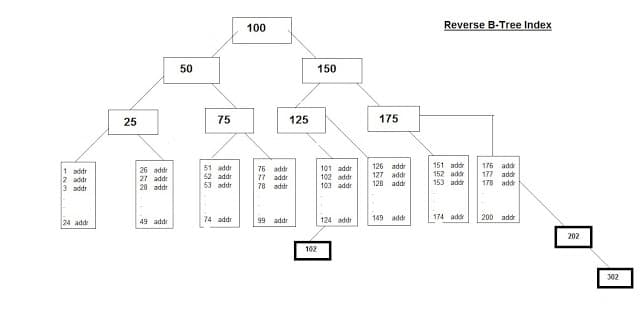
--> Reverse B-Tree Index
--> Bitmap index
--> Function based Index
--Nick
Same applies in databases too. An index is used to avoid wastage of time that is spent in searching for a particular record in a table.
For example, consider the following table
If you run the following query on this table:
select * from emp where empno=7844;
it will go and scan each and every block of data starting from the top row till bottom row and when it finds empno 6844, it gives the result. This is a small table, consider the same operation on a table with 10 million rows, it will definitely consume a lot of time. This can be reduced by using index. An index can be created as follows:
create index ind_1 on emp(empno);
In the above statement, we are telling oracle to create an index named ind_1 on empno filed of table emp.
When this index is created, one more table is formed in the back end that stores the address of each and every row. Following diagram will give a clean idea about it:
As shown in the diagram, every empno has a corresponding address which holds the address of each row of the emp table. Now whenever we want to extract row corresponding to a particular empno, we get the row very fastly compared to earlier method where we had no index.
This is how indexes are helpful in databases..
There are mainly four type of indexes which I will be discussing further in the comments.
They are:
--> B-Tree Index
--> Reverse B-Tree Index
--> Bitmap index
--> Function based Index
--Nick