
Tutorial : Hadoop -- Architecture
@neeraj-iAaNcG
•
Oct 24, 2024
Oct 24, 2024
1.1K
For other tutorials and index of tutorials in this series click here : <a href="https://www.crazyengineers.com/threads/tutorial-hadoop-main-thread.70394">Tutorial : Hadoop -- Main Thread</a>
Now as we are aware of the common terminologies that are involved, lets get on to the architecture of Hadoop.
Hadoop has two major components:
-> Distributed File System Component (Also called Hadoop Distributed File System)
-> MapReduce Component (which is a framework for performing calculations on data stored in distributed file system).
I am going to explain in brief about MapReduce component in this tutorial and then go on a detailed explanation of HDFS over two separate threads.
MapReduce Engine:
MapReduce is a technology from Google. MapReduce program consists of a map function and a reduce function. A scheduled MapReduce function is called as a MapReduce job.
A MapReduce job is broken into map tasks that run in parallel and reduce tasks that run in parallel too. This was a brief explanation of MapReduce. A detailed explanation of MapReduce will be covered in later tutorials.
Now lets go on to HDFS.
Hadoop Distributed File System (HDFS)
HDFS runs on top of the existing file system on each node of the Hadoop cluster. It is designed to handle very large files with streaming data access patterns.
The larger the file, the less time Hadoop spends seeking for the next data location on the disk and most times Hadoop runs at the limit of the bandwidth of the disks. As everyone would know, seeks are pretty expensive operations and are useful only when you only need to analyze a small subset of a data set.
Since, Hadoop is designed to run over the entire data set, it is best to minimize seeks by using large files. Hadoop is designed for streaming or sequential data access rather than random access.
Sequential data access means fewer seeks, since Hadoop only seeks the beginning of each block and begins reading sequentially from there.
Hadoop uses blocks to store file or parts of file as shows below:
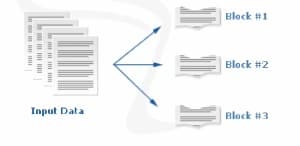
I am going to cover more about HDFS blocks and replication in the next tutorial.
Check in the Main thread here for links to other tutorials : <a href="https://www.crazyengineers.com/threads/tutorial-hadoop-main-thread.70394">Tutorial : Hadoop -- Main Thread</a>
Now as we are aware of the common terminologies that are involved, lets get on to the architecture of Hadoop.
Hadoop has two major components:
-> Distributed File System Component (Also called Hadoop Distributed File System)
-> MapReduce Component (which is a framework for performing calculations on data stored in distributed file system).
I am going to explain in brief about MapReduce component in this tutorial and then go on a detailed explanation of HDFS over two separate threads.
MapReduce Engine:
MapReduce is a technology from Google. MapReduce program consists of a map function and a reduce function. A scheduled MapReduce function is called as a MapReduce job.
A MapReduce job is broken into map tasks that run in parallel and reduce tasks that run in parallel too. This was a brief explanation of MapReduce. A detailed explanation of MapReduce will be covered in later tutorials.
Now lets go on to HDFS.
Hadoop Distributed File System (HDFS)
HDFS runs on top of the existing file system on each node of the Hadoop cluster. It is designed to handle very large files with streaming data access patterns.
The larger the file, the less time Hadoop spends seeking for the next data location on the disk and most times Hadoop runs at the limit of the bandwidth of the disks. As everyone would know, seeks are pretty expensive operations and are useful only when you only need to analyze a small subset of a data set.
Since, Hadoop is designed to run over the entire data set, it is best to minimize seeks by using large files. Hadoop is designed for streaming or sequential data access rather than random access.
Sequential data access means fewer seeks, since Hadoop only seeks the beginning of each block and begins reading sequentially from there.
Hadoop uses blocks to store file or parts of file as shows below:
I am going to cover more about HDFS blocks and replication in the next tutorial.
Check in the Main thread here for links to other tutorials : <a href="https://www.crazyengineers.com/threads/tutorial-hadoop-main-thread.70394">Tutorial : Hadoop -- Main Thread</a>