Intel C++ Compiler "icc : command not found" error in Ubuntu [Solved]
@rukawa-Y0pUkC
•
Oct 27, 2024
Oct 27, 2024
5.3K
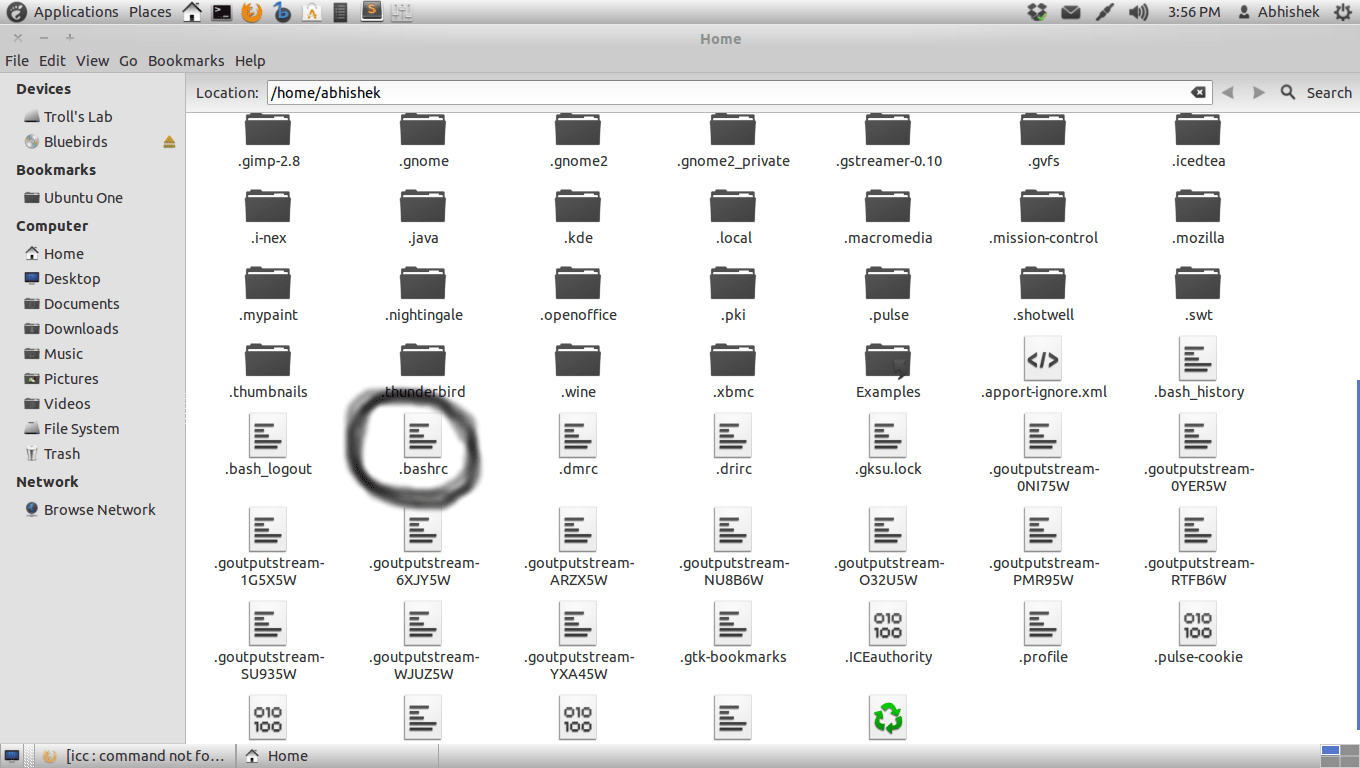
Hello everybody,
I've recently installed the intel's icc compiler, but I'm still unable to use it because everytime I try to compile my c programs using it I get the message :
icc : command not found
I reinstalled the icc compiler, but I still have the same problem.
Should I make some modifications somewhere in some file so that the operating system takes this newly unstalled software into account? What could be the source of the problem?
I have an UBUNTU 12.04 by the way.
I've recently installed the intel's icc compiler, but I'm still unable to use it because everytime I try to compile my c programs using it I get the message :
icc : command not found
I reinstalled the icc compiler, but I still have the same problem.
Should I make some modifications somewhere in some file so that the operating system takes this newly unstalled software into account? What could be the source of the problem?
I have an UBUNTU 12.04 by the way.